
Tesla GPU computing is delivering transformative increases in performance for a wide range of HPC industry segments.
The parallel processing capability of the GPU allows it to divide complex computing tasks into thousands of smaller tasks that can be run concurrently.
In addition to dramatic improvements in speed, GPUs also consume less power than conventional CPU-only clusters. GPUs deliver performance increases of 10x to 100x to solve problems in minutes instead of hours—while outpacing the performance of traditional computing with x86-based CPUs alone.
From climate modeling to advances in medical tomography, NVIDIA® Tesla GPUs are enabling a wide variety of segments in science and industry to progress in ways that were previously impractical, or even impossible, due to technological limitations.
NVIDIA P100 4-GPU and 8-GPU servers
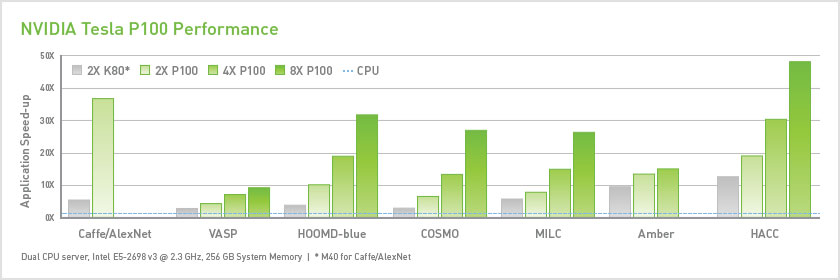
NVIDIA Tesla® P100 GPU accelerators are the most advanced available for datacenters. They tap into the new NVIDIA Pascal™ GPU architecture to deliver the world’s fastest compute node with higher performance than 100s of slower commodity nodes. Higher performance with fewer, but lightning-fast nodes enables datacenters to dramatically increase throughput while also saving money. With a proven track record of over 400 HPC applications accelerated—including 9 out of top 10—as well as all deep learning frameworks, every Nor-Tech HPC client can now deploy accelerators in their datacenters. These servers take advantage of NVIDIA’s NVLink technology which greatly enhanced GPU-to-GPU communication.
Multi-core programming with x86 CPUs is difficult and often results in marginal performance gain when going from 1 core to 4 cores to 16 cores. Beyond 4 cores, memory bandwidth becomes the bottleneck to further performance increases.
To harness the parallel computing power of GPUs, programmers can simply modify the performancecritical portions of an application to take advantage of the hundreds of parallel cores in the GPU. The rest of the application remains the same, making the most efficient use of all cores in the system. Running a function of the GPU involves rewriting that function to expose its parallelism, then adding a fewnew function-calls to indicate which functions will run on the GPU or the CPU. With these modifications, the performance-critical portions of the application can now run significantly faster on the GPU.
CUDA is NVIDIA’s parallel computing architecture. Applications that leverage the CUDA architecture can be developed in a variety of languages and APIs, including C, C++, Fortran, OpenCL, and DirectCompute. The CUDA architecture contains hundreds of cores capable of running many thousands of parallel threads, while the CUDA programming model lets programmers focus on parallelizing their algorithms and not the mechanics of the language.
The latest generation CUDA architecture, codenamed “Fermi”, is the most advanced GPU computing architecture ever built. With over three billion transistors, Fermi is making GPU and CPU co-processing pervasive by addressing the fullspectrum of computing applications.
With support for C++, GPUs based on the Fermi architecture make parallel processing easier and accelerate performance on a wider array of applications than ever before. Just a few applications that can experience significant performance benefits include ray tracing, finite element analysis, high-precision scientific computing, sparse linear algebra, sorting, and search algorithms.