Where will you store YOUR data?
Large computing jobs often require huge amounts of information and create exponential data growth. To address large storage needs, today’s data storage options must be reliable, scalable, cost effective, and easy to manage – ensuring data availability and recovery.
With this in mind, Nor-Tech has carefully chosen a combination of product lines in hard drives, DAS RAID systems, distributed file systems, storage area networking (SAN) solutions, network attached storage (NAS), and software to provide you with a wide variety of storage solutions.
Products
All Flash Storage
All-flash storage arrays vary in capacity, drive type, networking options, and storage-saving features, but they all improve performance. Initially it was only the large companies that could afford enterprise class flash; that is no longer the case. This technology is now accessible to organizations of all sizes.
Flash storage arrays offer these benefits:
- Enable the extreme data-mobility speeds that allow data to be seamlessly shared and accessed across functions.
- Prevent latency spikes during peak use times.
- Flexibility and scalability.
- Support faster, even real time, analytics: They can effortlessly handle enormous amounts of data.
- Reduce replacement costs.
- Significantly reduce the heat and physical footprint and eliminate ambient noise and vibration of traditional arrays.
- Enable organizations to easily migrate from traditional disk storage.
- Long-term time and cost savings.
All flash storage is the answer for applications that require instant access and no latency—meaning just about all applications.
Supermicro All Flash Super SBB Storage
![]() Supermicro has been a valued Nor-Tech partner for more than a decade; we are pleased to offer a range of Supermicro all flash storage options.
Supermicro has been a valued Nor-Tech partner for more than a decade; we are pleased to offer a range of Supermicro all flash storage options.
The new all-NVMe flash VSAN solution is based on the 1U Ultra SuperServer® 1028U-TN10RT+, which supports 10 NVMe SSDs with the industry’s first-to-market true hot-swap capability for enterprise mission-critical RAS applications.
 These Supermicro VSAN ready nodes are ideal for clients looking to create a simple-to-deploy and manage, blazing fast hyper-converged cluster with high-availability that is targeted for high-performance database and big data analytics applications that demand a high degree of compatibility, reliability, and serviceability.
These Supermicro VSAN ready nodes are ideal for clients looking to create a simple-to-deploy and manage, blazing fast hyper-converged cluster with high-availability that is targeted for high-performance database and big data analytics applications that demand a high degree of compatibility, reliability, and serviceability.
For even higher density all-NVMe flash systems, Supermicro offers a 2U SuperServer that supports 24 hot-swap NVMe SSDs and another that supports 48 hot-swap NVMe SSDs. Supermicro also introduced a new high-availability 2U dual-node system with support for 20 dual-port NVMe SSDs.
Direct Attached Storage Solutions (DAS)
Direct attached storage (DAS) is directly attached to the computer accessing that storage, unlike other types of storage where the storage is accessed over a network. Examples of DAS include: hard drives, optical storage, solid state drives (SSD), storage on external drives, and RAID arrays located physically in the computer. DAS has a 1:1 relationship between storage and host whereas SDS, DFS, SAN and NAS are many-to-many.
Advantages
- Low cost
- No network bottlenecks
- Very simple to implement
- No network hardware needed
- Easy expansion with JBOD
Disadvantages
- Limited to 1:1 storage-to-host ratio
- Limited scalability
Best Uses
- HPC storage right in cluster head node
- General file server storage right in the server
- Small scale storage
Software Defined Storage Solutions (SDS)
Many different storage systems can fall under the SDS category. Even DFS listed below falls under SDS. Software RAID could also fall under the SDS category. Two common SDS feature-rich offerings are Microsoft Storage Spaces and ZFS or ZFS on Linux (ZOL). Microsoft Storage Spaces is available in Windows Server and offers features like storage tiers, write-back cache, and parity space support for failover clusters, dual parity, and auto rebuild from storage pool free space.
Between ZFS and Microsoft Storage Spaces we find the features of ZFS the most interesting. ZFS has been around for more than a decade, it was originally developed by Sun Microsystems. ZFS is a file system, disk management system, software RAID, share management system all-in-one. ZFS is a copy on write FS. You change a file and ZFS will write a copy of that file to your disk, only after the copy is written without errors is the original file deleted. That way crashes during a write won’t corrupt the data on your disk. ZFS checksums all data and metadata which helps ZFS detect and correct errors in stored data resulting from bit rot. It will detect and correct bit rot that hard drive SMART technology often misses. ZFS has more redundancy available than even RAID 6 allows; triple parity instead of double parity. Snapshots, deduplication, compression and capacities in the exabyte range are all included.
Advantages
- Low cost
- Fast to deploy
- Massively scalable
- Can provide high reliability beyond double parity
- Not limited to capabilities of hardware controllers
- Can provide replication both locally and remotely
- Tiered storage capable
- Can snapshot data
Disadvantages
- Makes no sense in small environments
- Can make data recovery complex
- Requires sophisticated data recovery and regular backups
Best Uses
- Can provide HA(high availability) in some cases
- Good where data growth will be key
- Excellent where high reliability and redundancy is needed
- Good where tiered storage is a benefit
- Good if replication is important or snapshots are needed
Distributed File Storage Solutions (DFS)

Hadoop is an open-source software defined storage project administered by the Apache Software Foundation. Hadoop’s contributors work for some of the world’s biggest technology companies like Yahoo and Google. The open-source community as well as commercial companies providing commercial versions of Hadoop have produced a genuinely innovative platform for consolidating, combining and understanding data. Enterprises today collect and generate more data than ever before. Relational and data warehouse products excel at OLAP and OLTP workloads over structured data. Hadoop was designed to deal with unstructured data which needs: scalable, reliable storage and analysis of both structured and complex data. As a result, many enterprises deploy Hadoop alongside their legacy IT systems, allowing them to combine old and new data sets in powerful new ways. Technically, Hadoop consists of two key services: reliable data storage using the Hadoop Distributed File System (HDFS) and high-performance parallel data processing using a technique called MapReduce. Hadoop runs on a collection of commodity, shared-nothing servers. Unlike HPC which has centralized storage and distributed compute, Hadoop uses both distributed storage and distributed compute. Hadoop breaks your big data into blocks which is stored in distributed servers which handle both the storage and compute jobs. You can add or remove servers in a Hadoop cluster at will; the system detects and compensates for hardware or system problems on any server. Hadoop, in other words, is self-healing. Hadoop can automatically store multiple copies of data which increases reliability. It can deliver data – and can run large-scale, high-performance processing jobs – in spite of system changes or failures. You can scale up your Hadoop system by just adding nodes. This tutorial does a good job of helping you grasp the map/reduce concept http://www.tutorialspoint.com/hadoop/hadoop_mapreduce.htm
Main Elements of Hadoop
- Hadoop Common – utilities and libraries referenced by other Hadoop software
- Hadoop Distributed File System (HDFS) – Java-based code that stores data on multiple machines with prior structuring
- MapReduce – It consists of two parts: map and reduce. Map converts a set of data into a different dataset; separate elements are put into tuples (key/value pairs). Reduce takes those data from the Map operation and combines them into smaller sets of tuples
- YARN – A resource manager for scheduling and resource management. YARN means (Yet Another Resource Negotiator)
Advantages
- Low cost per byte
- Excellent for processing unstructured data
- Provides storage close to compute resources
- Scales to massive compute and storage sizes
Disadvantages
- Can be complex to implement and manage
Best Uses
- Can provide HA(high availability) in some cases
- Consider Hadoop for data volumes in the TB or PB range
- If you have mixed data types in your data
- If your organization has Java programming skills (how Hadoop is written)
- Your data growth in the future will be big
Gluster

GlusterFS is a very sophisticated GPLv3 file system that uses FUSE (File System in User Space). It allows you to aggregate disparate storage devices, which GlusterFS refers to as “storage bricks”, into a single storage pool or namespace. It is what is sometimes referred to as a “meta-file-system” which is a file system built on top of another file system. The storage in each brick is formatted using a local file system such as ext3 or ext4, and then GlusterFS uses those file systems for storing data (files and directories). GlusterFS is very interesting for many reasons. It allows you to aggregate and use disparate storage in a variety of ways. The nodes themselves are stateless; they don’t talk to each other. GlusterFS uses an elastic hashing algorithm instead of either a central or distributed metadata model. It is in use at a number of sites for very large storage arrays, for high performance computing, and for specific application arrays such as bioinformatics that have particular IO patterns (particularly nasty IO patterns in many cases). GlusterFS has a client and server structure. Servers are the storage bricks with each server running a GlusterFSD daemon to export the local fs as a volume. The GlusterFS client process connects to the servers via a custom protocol over TCP/IP or InfiniBand and creates composite virtual volumes from multiple remote servers. Files can be stored whole or stripped across multiple servers. The final volume can be mounted by the client using FUSE with NFS v3 or via gfapi client library. Native protocols can be re-exported via NFS v4 server, SAMBA, OpenStack storage (Swift) protocol using the UFO (Unified File and Object) translator. A lot of utility for GlusterFS comes from translators including file-based mirroring and replication, file load balancing, file stripping, scheduling, volume failover, disk caching, quotas, and snapshots.
Advantages
- No metadata server – it is fully distributed
- Scales to 100s of petabytes
- High availability – uses replication and heals automatically
- Gluster has no kernel dependencies
- Easy to install and manage
Disadvantages
- Lose of a single server will cause loss of access to all files stored on that server
- If files are larger than sub-volume the write will fail
Best Uses
- Can provide HA(high availability)
- You have petabytes of data to manage
- Simple to use, basically a scale-out NAS
- Clients talk to Gluster storage via NFS
Lustre Intel® Solutions for Lustre* Software Reseller

 The Lustre file system is used for many clusters, but it is best known for powering 60% of the top 100 largest high-performance computing (HPC) clusters in the world, with some systems supporting over ten thousand clients, many petabytes (PB) of storage and many of these systems nearing or over hundreds of gigabytes per second (GB/sec) of I/O throughput. The Lustre parallel file system is well suited for large HPC cluster environments and has capabilities that fulfill important I/O subsystem requirements. The primary use is for temporary scratch storage and not long term or archival storage. The Lustre file system is designed to provide cluster client nodes with shared access to file system data in parallel. Lustre enables high performance by allowing system architects to use any common storage technologies along with high-speed interconnects. Lustre file systems also can scale well as an organization’s storage needs grow. And by providing multiple paths to the physical storage, the Lustre file system can provide high availability for HPC clusters. Unlike GlusterFS and Ceph, Lustre uses metadata servers whose job it is to direct clients read/write tasks to the proper locations to read/write on the (object storage server)OSS and (object storage target)OST.
The Lustre file system is used for many clusters, but it is best known for powering 60% of the top 100 largest high-performance computing (HPC) clusters in the world, with some systems supporting over ten thousand clients, many petabytes (PB) of storage and many of these systems nearing or over hundreds of gigabytes per second (GB/sec) of I/O throughput. The Lustre parallel file system is well suited for large HPC cluster environments and has capabilities that fulfill important I/O subsystem requirements. The primary use is for temporary scratch storage and not long term or archival storage. The Lustre file system is designed to provide cluster client nodes with shared access to file system data in parallel. Lustre enables high performance by allowing system architects to use any common storage technologies along with high-speed interconnects. Lustre file systems also can scale well as an organization’s storage needs grow. And by providing multiple paths to the physical storage, the Lustre file system can provide high availability for HPC clusters. Unlike GlusterFS and Ceph, Lustre uses metadata servers whose job it is to direct clients read/write tasks to the proper locations to read/write on the (object storage server)OSS and (object storage target)OST.
Lustre is open sourced but has support available from companies like Intel, and commercial appliance versions available from Seagate with their ClusterStor Parallel Storage System (formerly Xyratex). The open source versions are community supported by opensfs.org and lustre.org.
Advantages
- Striping a file across multiple OSTs increases bandwidth and available storage size
- Can scale to massive storage and incredible speed. Can support tens of thousands of clients
- Up to 512 PB in one file system
- Up to 32 PB in one file
- Up to 2TB/s already in production
- Up to 10 M files in one directory, and 2B files in the file system
- Up to 25K clients in production now
Disadvantages
- Striping a file across multiple OSTs increases network traffic and drives the need for low-latency expensive networks like InfiniBand
- Striping a file across multiple OSTs increases the risk of file damage because parts of the file are spread across multiple OST hardware targets.
Best Uses
- Due to fast access, Lustre makes excellent scratch storage for clusters
Ceph

The massive storage capability of Ceph can revitalize your organization’s IT infrastructure and your ability to manage vast amounts of data. If your organization runs applications with different storage interface needs, Ceph is for you! Ceph’s foundation is the Reliable Autonomic Distributed Object Store (RADOS), which provides your applications with object, block, and file system storage in a single unified storage cluster-making Ceph flexible, highly reliable, and easy for you to manage. Ceph’s RADOS provides you with extraordinary data storage scalability-thousands of client hosts or KVMs accessing petabytes to exabytes of data. Ceph is completely distributed without any single point of failure, scalable to exabyte levels, and is open sourced. Each one of your applications can use the object, block or file system interfaces to the same RADOS cluster simultaneously, which means your Ceph storage system serves as a flexible foundation for all of your data storage needs. You can use Ceph free, and deploy it on economical commodity hardware.
OBJECT-BASED STORAGE
Organizations like object-based storage when deploying large scale storage systems, because it stores data more efficiently. Object-based storage systems separate the object namespace from the underlying storage hardware—this simplifies data migration.
WHY IT MATTERS
By decoupling the namespace from the underlying hardware, object-based storage systems enable you to build much larger storage clusters. You can scale out object-based storage systems using economical commodity hardware, and you can replace hardware easily when it malfunctions or fails.
THE CEPH DIFFERENCE
Ceph’s CRUSH algorithm liberates storage clusters from the scalability and performance limitations imposed by centralized data table mapping. It replicates and re-balances data within the cluster dynamically—eliminating this tedious task for administrators, while delivering high-performance and infinite scalability.
CEPH ARCHITECTURE
A minimum Ceph storage cluster has one monitor node (MON), and an Object Storage Server (OSD). Administration tasks are done on an admin node, which can also be a MON node. MON nodes should be an odd number because they vote and determine which OSDs are in the cluster and working. If just Ceph Block Device or Ceph Object Storage is used, no separate metadata servers (MDS) are needed. If Ceph File System is stored then separate scalable MDS servers are needed.
Advantages
- Provides strong data reliability for mission-critical operations
- Scales to 100s of petabytes
- Fast with TB/sec aggregate throughput
- Can handle billions of files
- File sizes can be from bytes to terabytes
- Enterprise reliability
- Unified storage (object, block, and file)
Disadvantages
- A normal installation can require beefy networks, for example 2 to 4 10Gbe on each server with each VLAN’d across two switches, so you can lose a switch with losing either network
- Non-trivial as far as the number of switches and servers required for a best practice Ceph storage system
- Not the most efficient at using CPUs and SSD, but is getting better
Best Uses
- Can Provide HA(high availability)
- Deployed Ceph storage of ~ 30PB have been tested
- Cloud storage services
- Can perform unified storage (object, block, and file), this is rare
Storage Area Network (SAN)
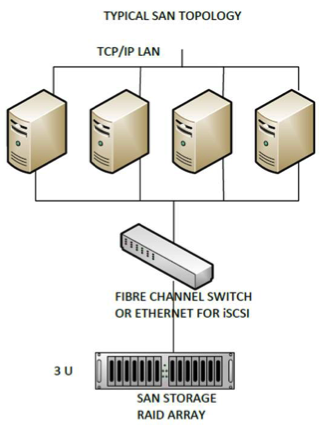 SAN storage locates storage resources off the common user network and onto an independent, high performance network. This gives each server access to shared storage as if the drive were directly attached to the server. When a host accesses the SAN storage it sends out a block-based access to the SAN. Fibre Channel was the network of choice originally for SAN systems but it is expensive and complex to manage. The birth of iSCSI, which is encapsulated SCSI commands within IP packets for transmission over Ethernet, has gained in popularity in recent years. IT administrators like iSCSI because they are already familiar with Ethernet and they don’t have to deal with learning, supporting, and purchasing Fibre Channel equipment. The main benefit of a SAN is that raw storage can be treated as a pool of resources which can be centrally managed and allocated on an as needed basis. SANs are highly scalable when additional storage is needed. The biggest disadvantage of SANs are cost and complexity. The terms SAN and NAS are often confused with one another because the acronyms are so similar. NAS consists of a storage appliance that is plugged directly into a network switch. Although there are exceptions, NAS appliances are often used as file servers.
SAN storage locates storage resources off the common user network and onto an independent, high performance network. This gives each server access to shared storage as if the drive were directly attached to the server. When a host accesses the SAN storage it sends out a block-based access to the SAN. Fibre Channel was the network of choice originally for SAN systems but it is expensive and complex to manage. The birth of iSCSI, which is encapsulated SCSI commands within IP packets for transmission over Ethernet, has gained in popularity in recent years. IT administrators like iSCSI because they are already familiar with Ethernet and they don’t have to deal with learning, supporting, and purchasing Fibre Channel equipment. The main benefit of a SAN is that raw storage can be treated as a pool of resources which can be centrally managed and allocated on an as needed basis. SANs are highly scalable when additional storage is needed. The biggest disadvantage of SANs are cost and complexity. The terms SAN and NAS are often confused with one another because the acronyms are so similar. NAS consists of a storage appliance that is plugged directly into a network switch. Although there are exceptions, NAS appliances are often used as file servers.
Note: A SAN is more complex and costly then a NAS. A SAN consists of dedicated cabling either Fibre Channel or Ethernet, dedicated switches and storage hardware. SANs are highly scalable and allow storage to be exposed as LUNs. In contrast, NAS storage usually exposes storage as a file system although some NAS appliances do support block storage.
Advantages
- A SAN can scale into the 100s of terabytes
- Centralized storage leads to better storage management and reliable data backup
Disadvantages
- SANs tend to be expensive; normally too high for small scale environments
- SANs require either Fibre Channel or iSCSI for networking and the network is normally dedicated to storage so it can increase costs
- Management of SAN storage requires a degree of technical expertise
- For capacities greater than 100s of terabytes consider Ceph; it is more versatile and lower cost
Best Uses
- Medium to large businesses with a need for centralized managed storage
- Good for storage capacities from 10s to 100s of terabytes
- Transaction intensive databases like ERP or CRM do well with SAN storage
Network Attached Storage (NAS)
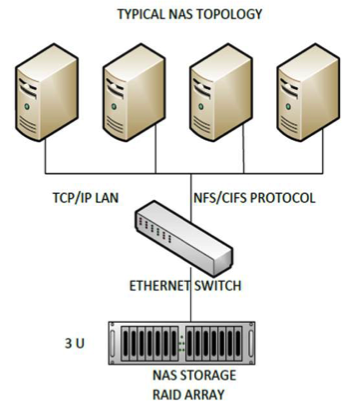 NAS storage is a type of dedicated file storage device that provides local area networks nodes with file-based storage through standard Ethernet networks. NAS storage devices typically do not have a keyboard or display and are configured and managed with a browser-based utility program or in some cases command line instructions. Each NAS can reside on a LAN as an independent network node with its own IP address. An important benefit of the NAS is its ability to provide multiple clients on the network with access to the same files. Prior to NAS, storage enterprises typically had hundreds or even thousands of discrete file servers that had to be separately configured and maintained. Today when more storage is required NAS devices can simply be given larger disks or clustered together to provide more vertical scalability and horizontal scalability.
NAS storage is a type of dedicated file storage device that provides local area networks nodes with file-based storage through standard Ethernet networks. NAS storage devices typically do not have a keyboard or display and are configured and managed with a browser-based utility program or in some cases command line instructions. Each NAS can reside on a LAN as an independent network node with its own IP address. An important benefit of the NAS is its ability to provide multiple clients on the network with access to the same files. Prior to NAS, storage enterprises typically had hundreds or even thousands of discrete file servers that had to be separately configured and maintained. Today when more storage is required NAS devices can simply be given larger disks or clustered together to provide more vertical scalability and horizontal scalability.
Advantages
- Good for file storage using NFS and CIFS protocols
- Entry level NAS is low cost
- NAS uses existing networks so cost is saved with no need for a dedicated network
- Provides centralized storage that can be managed with low technical skill requirements
Disadvantages
- Not a good storage for transaction intensive databases like, ERP or CRM
- Since a common Ethernet network handles normal and storage traffic, performance can suffer in busy network scenarios
Best Uses
- Good solution when centralized low cost storage is needed
- Good solution when centralized storage is needed but little technical expertise is available
More Differences
NAS |
SAN |
| Almost any machine that can connect to the LAN (or is interconnected to the LAN through a WAN) can use NFS, CIFS, or HTTP protocol to connect to a NAS and share files. | Only server class devices with iSCSI or Fibre Channel can connect to the SAN. The Fibre Channel of the SAN has a limit of around 10km at best. |
| A NAS identifies data by file name and byte offsets, transfers file data or file metadata (file’s owner, permissions, creation data, etc.), and handles security, user authentication, file locking, etc. | A SAN addresses data by disk block number and transfers raw disk blocks. |
| A NAS allows greater sharing of information especially between disparate operating systems such as Linux, Unix and Windows. | File sharing is operating system dependent and does not exist in many operating systems. |
| File System managed by NAS head unit | File system managed by servers |
| Backups and mirrors (utilizing features like NetApp’s Snapshots) are done on files, not blocks, for a savings in bandwidth and time. A Snapshot can be tiny compared to its source volume | Backups and mirrors require a block-by-block copy, even if blocks are empty. A mirror machine must be equal to or greater in capacity compared to the source volume. |